Что такое JSON в Python
- Что такое JSON и почему он так популярен?
- Структура JSON
- Работа с JSON в Python через встроенный модуль json
- Соответствие типов данных Python и JSON
- Продвинутые возможности при работе с JSON
- Визуализация: Популярные форматы обмена данными
- Реальные примеры использования JSON в Python
- Распространенные проблемы и их решения
- Лучшие практики при работе с JSON в Python
- Альтернативные библиотеки для работы с JSON
- Преимущества JSON перед другими форматами данных
- Путь к JSON-мастерству: Ключевые практические шаги
- Часто задаваемые вопросы (FAQ)
Что такое JSON и почему он так популярен?
JSON (JavaScript Object Notation) — легковесный формат обмена данными, который легко читается как человеком, так и машиной. Представьте, что вам нужно быстро передать структурированную информацию между веб-сервисами — JSON станет идеальным решением.
Главные преимущества JSON:
- Простота синтаксиса — понятная структура с минимумом символов
- Универсальность — поддерживается практически всеми языками программирования
- Компактность — занимает меньше места по сравнению с XML
- Человекочитаемость — легко просматривать и редактировать вручную
Интересный факт: несмотря на название, содержащее «JavaScript», JSON совершенно независим от этого языка программирования и используется повсеместно в современной разработке.

Структура JSON
JSON построен на двух основных структурах:
1. JSON-объект
Объект представляет собой набор пар «ключ-значение», заключенный в фигурные скобки. Ключи всегда строки в двойных кавычках, а значения могут быть разных типов:
{
«имя»: «Иван»,
«возраст»: 30,
«программист»: true,
«языки»: [«Python», «JavaScript», «Go»],
«адрес»: {
«город»: «Москва»,
«индекс»: «123456»
}
}
2. JSON-массив
Массив — это упорядоченный список значений, заключенный в квадратные скобки:
[
«Python»,
«JavaScript»,
«Java»,
«C++»
]
В JSON допустимы следующие типы данных:
- Строки (в двойных кавычках)
- Числа (целые и с плавающей точкой)
- Объекты (в фигурных скобках)
- Массивы (в квадратных скобках)
- Логические значения (true/false)
- null
Работа с JSON в Python через встроенный модуль json
Python предоставляет встроенный модуль json, который упрощает работу с этим форматом. Ключевые операции — это сериализация (преобразование Python-объектов в JSON) и десериализация (преобразование JSON обратно в Python-объекты). Об остальных инструментах разработчиков более подробно всегда можно узнать на курсах Python.
Для начала работы нужно импортировать модуль:
import json
Сериализация в Python: Превращаем Python-объекты в JSON
Основные функции для сериализации:
| Функция | Назначение | Основной параметр | Результат | Пример использования |
| json.dumps() | Преобразует Python-объект в JSON-строку | Python-объект | Строка | json_str = json.dumps(data) |
| json.dump() | Записывает Python-объект в JSON-файл | Python-объект и файловый объект | Ничего (запись в файл) | json.dump(data, file_obj) |
| json.loads() | Преобразует JSON-строку в Python-объект | JSON-строка | Python-объект | data = json.loads(json_str) |
| json.load() | Читает JSON из файла в Python-объект | Файловый объект | Python-объект | data = json.load(file_obj) |
Пример сериализации словаря в JSON-строку:
import json
# Словарь Python
user_data = {
«имя»: «Анна»,
«возраст»: 28,
«навыки»: [«Python», «SQL», «Machine Learning»],
«активен»: True
}
# Сериализация в JSON-строку
json_string = json.dumps(user_data, ensure_ascii=False, indent=4)
print(json_string)
Результат выполнения:
{
«имя»: «Анна»,
«возраст»: 28,
«навыки»: [
«Python»,
«SQL»,
«Machine Learning»
],
«активен»: true
}
Обратите внимание на параметры:
- ensure_ascii=False — позволяет корректно отображать не-ASCII символы (например, кириллицу)
- indent=4 — форматирует JSON с отступами для лучшей читаемости
Десериализация: Из JSON в Python-объекты
Чтобы преобразовать JSON-строку обратно в Python-объект:
# JSON-строка
json_data = ‘{«имя»: «Иван», «возраст»: 30, «программист»: true}’
# Десериализация в Python-объект
python_obj = json.loads(json_data)
print(type(python_obj)) # <class ‘dict’>
print(python_obj[«имя»]) # Иван
Работа с JSON-файлами
Часто требуется сохранять и загружать данные в/из JSON-файлов:
# Запись в файл
user = {
«id»: 1,
«username»: «python_lover»,
«email»: «example@example.com»,
«projects»: [«Web API», «Data Analysis», «Automation»]
}
# Сохраняем в файл
with open(‘user_data.json’, ‘w’, encoding=’utf-8′) as file:
json.dump(user, file, ensure_ascii=False, indent=2)
# Чтение из файла
with open(‘user_data.json’, ‘r’, encoding=’utf-8′) as file:
loaded_user = json.load(file)
print(loaded_user[‘username’]) # python_lover
Важно: всегда используйте параметр encoding=’utf-8′ при работе с файлами, чтобы корректно обрабатывать символы разных языков.
Соответствие типов данных Python и JSON
При сериализации и десериализации происходит автоматическое преобразование типов:
Python → JSON
- dict → object
- list, tuple → array
- str → string
- int, float → number
- True → true
- False → false
- None → null
JSON → Python
- object → dict
- array → list
- string → str
- number (int) → int
- number (real) → float
- true → True
- false → False
- null → None

Продвинутые возможности при работе с JSON
Дополнительные параметры сериализации
Модуль json предлагает несколько полезных параметров для функций dumps() и dump():
data = {«результаты»: [1, 2, 3, 4, 5], «статус»: «завершено»}
# Сортировка ключей
print(json.dumps(data, sort_keys=True))
# Компактный формат (без пробелов)
print(json.dumps(data, separators=(‘,’, ‘:’)))
# Более читаемый формат с отступами
print(json.dumps(data, indent=4))
Работа с пользовательскими объектами
Стандартно json не умеет сериализовать пользовательские классы. Рассмотрим три способа решения этой проблемы:
Способ 1: Использование функции default
class User:
def __init__(self, name, age):
self.name = name
self.age = age
# Функция для преобразования объекта в словарь
def user_to_json(obj):
if isinstance(obj, User):
return {«name»: obj.name, «age»: obj.age}
raise TypeError(f»Объект типа {type(obj)} не сериализуется»)
# Создаем пользователя
user = User(«Елена», 25)
# Сериализуем с помощью custom-конвертера
json_data = json.dumps(user, default=user_to_json)
print(json_data) # {«name»: «Елена», «age»: 25}
Способ 2: Создание класса JSONEncoder
class CustomJSONEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, User):
return {«name»: obj.name, «age»: obj.age}
return super().default(obj)
# Используем наш енкодер
json_data = json.dumps(user, cls=CustomJSONEncoder)
print(json_data) # {«name»: «Елена», «age»: 25}
Способ 3: Добавление метода в класс
class UserWithJSON:
def __init__(self, name, age):
self.name = name
self.age = age
def to_json(self):
return {«name»: self.name, «age»: self.age}
# Сериализация
user = UserWithJSON(«Максим», 30)
json_data = json.dumps(user.to_json())
print(json_data) # {«name»: «Максим», «age»: 30}
Кастомная десериализация JSON
При десериализации также можно указать, как преобразовывать JSON в пользовательские объекты:
json_str = ‘{«name»: «Иван», «age»: 35}’
def json_to_user(json_dict):
return User(json_dict[‘name’], json_dict[‘age’])
# Десериализация с помощью object_hook
user_data = json.loads(json_str, object_hook=json_to_user)
print(type(user_data)) # <class ‘__main__.User’>
print(user_data.name) # Иван
Визуализация: Популярные форматы обмена данными
Сравнение популярности форматов данных (%):
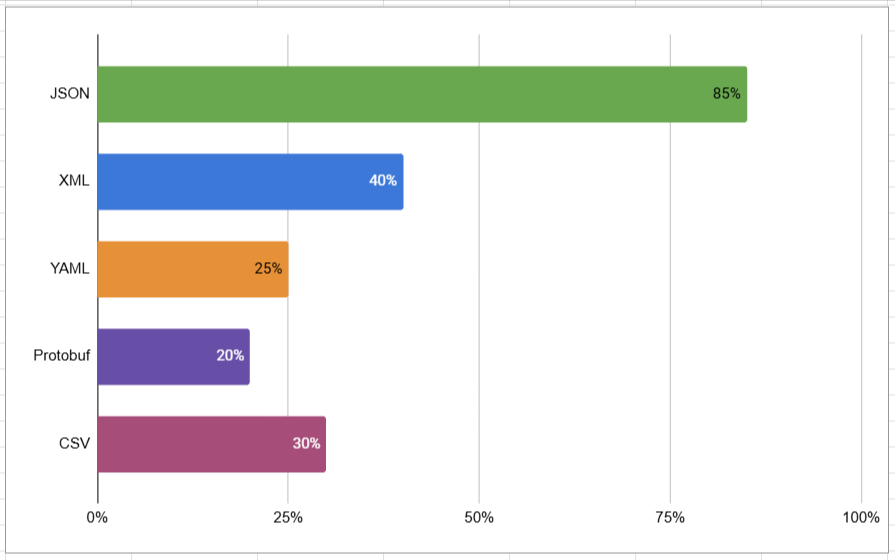
Реальные примеры использования JSON в Python
Пример 1: Работа с REST API
Один из самых распространенных сценариев использования JSON — взаимодействие с веб-сервисами:
import requests
import json
# Запрос к API
response = requests.get(‘https://api.github.com/users/python’)
# Проверка успешности запроса
if response.status_code == 200:
# Данные уже десериализованы в словарь Python
user_data = response.json()
print(f»Имя пользователя: {user_data[‘login’]}»)
print(f»Количество репозиториев: {user_data[‘public_repos’]}»)
# Можем сохранить эти данные в файл
with open(‘github_user.json’, ‘w’) as file:
json.dump(user_data, file, indent=2)
else:
print(f»Ошибка: {response.status_code}»)
Пример 2: Конфигурационные файлы
JSON часто используется для хранения настроек приложения:
# config.json
{
«database»: {
«host»: «localhost»,
«port»: 5432,
«user»: «admin»,
«password»: «secret»,
«db_name»: «myapp»
},
«api_keys»: {
«twitter»: «xyz123»,
«google»: «abc456»
},
«debug_mode»: true
}
# Python-код для работы с конфигурацией
import json
# Загрузка конфигурации
with open(‘config.json’, ‘r’) as config_file:
config = json.load(config_file)
# Использование значений из конфигурации
db_host = config[‘database’][‘host’]
twitter_api_key = config[‘api_keys’][‘twitter’]
is_debug = config[‘debug_mode’]
print(f»Подключение к БД на {db_host}»)
Распространенные проблемы и их решения
Проблема 1: Ошибки при сериализации сложных объектов
Если вы пытаетесь сериализовать объект с вложенными пользовательскими классами, могут возникать ошибки:
class Address:
def __init__(self, city, street):
self.city = city
self.street = street
class Person:
def __init__(self, name, address):
self.name = name
self.address = address # Объект класса Address
# Создаем объекты
address = Address(«Москва», «Ленина»)
person = Person(«Алексей», address)
# Попытка сериализации вызовет ошибку
try:
json_data = json.dumps(person)
except TypeError as e:
print(f»Ошибка: {e}»)
# Решение — рекурсивный конвертер
def complex_encoder(obj):
if hasattr(obj, «__dict__»):
return obj.__dict__
raise TypeError(f»Не могу сериализовать {obj}»)
# Теперь сработает
json_data = json.dumps(person, default=complex_encoder)
print(json_data) # {«name»: «Алексей», «address»: {«city»: «Москва», «street»: «Ленина»}}
Проблема 2: Циклические ссылки
Если объекты ссылаются друг на друга, стандартная сериализация не сработает:
class Node:
def __init__(self, name):
self.name = name
self.connections = []
def connect_to(self, other_node):
self.connections.append(other_node)
other_node.connections.append(self)
# Создаем узлы и соединяем их
node1 = Node(«Node 1»)
node2 = Node(«Node 2»)
node1.connect_to(node2) # Теперь каждый узел ссылается на другой
# Попытка сериализации вызовет ошибку из-за циклических ссылок
try:
json_data = json.dumps(node1, default=lambda o: o.__dict__)
except RecursionError as e:
print(f»Ошибка: {e}»)
# Решение — отслеживание уже обработанных объектов
def recursive_encoder(obj, visited=None):
if visited is None:
visited = set()
obj_id = id(obj)
if obj_id in visited:
return «Циклическая ссылка»
visited.add(obj_id)
if hasattr(obj, «__dict__»):
result = {}
for key, value in obj.__dict__.items():
if isinstance(value, list):
result[key] = [
recursive_encoder(item, visited.copy())
for item in value
]
else:
result[key] = recursive_encoder(value, visited.copy())
return result
return obj
# Теперь сериализация сработает
json_data = json.dumps(node1, default=lambda o: recursive_encoder(o))
print(json_data)

Лучшие практики при работе с JSON в Python
- Используйте контекстные менеджеры при работе с файлами для гарантированного закрытия файловых дескрипторов
- Указывайте кодировку UTF-8 для корректной работы с не-ASCII символами
- Обрабатывайте исключения при разборе JSON, чтобы корректно реагировать на некорректный формат
- Валидируйте данные перед сериализацией и после десериализации, особенно если источник ненадежен
- Используйте indent при отладке для лучшей читаемости
- Создавайте общие сериализаторы для пользовательских классов, если работаете с ними часто
Пример валидации и обработки ошибок:
def safe_json_load(json_string):
try:
data = json.loads(json_string)
# Простая валидация
if not isinstance(data, dict):
return None, «Ожидался JSON-объект»
required_fields = [«username», «email»]
for field in required_fields:
if field not in data:
return None, f»Отсутствует обязательное поле: {field}»
return data, None
except json.JSONDecodeError as e:
return None, f»Некорректный JSON: {str(e)}»
# Использование
test_json = ‘{«username»: «user1», «email»: «test@example.com»}’
data, error = safe_json_load(test_json)
if error:
print(f»Ошибка: {error}»)
else:
print(f»Данные успешно загружены: {data}»)
Альтернативные библиотеки для работы с JSON
Хотя встроенный модуль json покрывает большинство задач, существуют альтернативы с дополнительными возможностями:
- ujson — ультрабыстрый JSON-парсер, написанный на C
- simplejson — расширенная версия стандартного модуля json с дополнительными функциями
- orjson — быстрый, правильный JSON-парсер для Python с акцентом на производительность
Пример использования ujson для повышения производительности:
# pip install ujson
import ujson
import time
import json
# Создаем большой словарь для тестирования
big_dict = {f»key_{i}»: f»value_{i}» for i in range(100000)}
# Стандартный json
start = time.time()
json_str = json.dumps(big_dict)
end = time.time()
print(f»Стандартный json: {end — start:.4f} секунд»)
# ujson
start = time.time()
ujson_str = ujson.dumps(big_dict)
end = time.time()
print(f»ujson: {end — start:.4f} секунд»)
Преимущества JSON перед другими форматами данных
Сравним JSON с другими популярными форматами:
- JSON vs XML:
- JSON легче и компактнее
- JSON проще парсить и создавать
- XML поддерживает более сложные структуры и имеет встроенную схему валидации
- JSON vs YAML:
- JSON стандартизирован и широко поддерживается
- YAML более читабелен и поддерживает комментарии
- YAML чувствителен к отступам, что может вызывать ошибки
- JSON vs Binary форматы (Protobuf, MessagePack):
- JSON человекочитаем
- Бинарные форматы более компактны и быстрее обрабатываются
- Бинарные форматы требуют дополнительных схем/определений типов
Путь к JSON-мастерству: Ключевые практические шаги
Работа с JSON в Python — это навык, который развивается от базового понимания до продвинутых техник. Давайте подведем итоги и наметим конкретные шаги для совершенствования.
- Освойте основы — научитесь сериализовать и десериализовать простые структуры данных
- Разработайте стратегию для работы с пользовательскими классами через custom encoders
- Автоматизируйте валидацию JSON-данных, особенно при работе с внешними API
- Профилируйте производительность — определите узкие места и, при необходимости, используйте оптимизированные библиотеки
- Разработайте единую инфраструктуру для работы с JSON в проекте, чтобы избежать дублирования кода
Самое важное — практика. Начните с простых задач, постепенно переходя к более сложным сценариям. JSON — это не просто формат данных, а универсальный инструмент коммуникации между системами, и хорошее понимание его принципов значительно расширит ваши возможности как Python-разработчика.
Как сказал один опытный разработчик: «JSON прекрасен не своей сложностью, а своей простотой. Его сила в том, что он решает реальные проблемы обмена данными с минимальными затратами.»
Часто задаваемые вопросы (FAQ)
Как обрабатывать даты и время в JSON?
JSON не имеет встроенного типа для дат и времени. Стандартный подход — преобразовывать даты в строки в формате ISO 8601 (например, «2023-11-15T14:30:00Z») при сериализации и затем преобразовывать их обратно при десериализации. Пример с использованием модуля datetime:
import json
from datetime import datetime
# Функция сериализации для datetime
def serialize_datetime(obj):
if isinstance(obj, datetime):
return obj.isoformat()
raise TypeError(f»Тип {type(obj)} не сериализуется»)
# Преобразуем объект с датой в JSON
data = {«name»: «События», «created_at»: datetime.now()}
json_str = json.dumps(data, default=serialize_datetime)
# При десериализации нужно распознать строки с датами
def deserialize_datetime(json_dict):
for key, value in json_dict.items():
if key.endswith(‘_at’) and isinstance(value, str):
try:
json_dict[key] = datetime.fromisoformat(value)
except ValueError:
pass # Не удалось преобразовать, оставляем как строку
return json_dict
# Преобразуем JSON обратно в объект
parsed_data = json.loads(json_str, object_hook=deserialize_datetime)
Можно ли хранить бинарные данные в JSON?
JSON работает только с текстовыми данными, поэтому бинарные данные (например, изображения или аудио) нужно кодировать. Наиболее распространенный подход — кодирование в Base64:
import json
import base64
# Чтение бинарного файла
with open(‘image.jpg’, ‘rb’) as image_file:
binary_data = image_file.read()
# Кодирование в Base64 и сохранение в JSON
data = {
«filename»: «image.jpg»,
«content_type»: «image/jpeg»,
«data

Что такое баг и баг-репорт Баг (от английского "bug" — жук, насекомое) — это дефект или ошибка в программном обеспечении, которая приводит к неожиданному или нежелательному поведению системы. Термин впервые был использован программистом Грейс Х...
Принципы работы SDLC и почему им пользуются Представьте себе строительство небоскреба без архитектурного плана. Звучит абсурдно, не правда ли? Однако именно так выглядит разработка программного обеспечения без применения принципов SDLC. Каждый...
Selenium: Основы и история развития Selenium представляет собой набор инструментов с открытым исходным кодом, предназначенный для автоматизации тестирования веб-приложений. Проект был создан в 2004 году Джейсоном Хаггинсом в компании ThoughtWor...
Что такое Story в Jira: основные принципы Story (пользовательская история) в Jira — это тип задачи, который описывает функциональность системы с точки зрения конечного пользователя. В отличие от технических задач, Story фокусируется на том, кто...
Что такое эпик в Agile и Jira Эпик в Jira представляет собой крупную пользовательскую историю или инициативу, которая слишком велика для выполнения в рамках одного спринта и требует разбиения на более мелкие, управляемые задачи. Как отмечает Ма...
Что такое Jira: система управления проектами и отслеживания задач Jira представляет собой мощную платформу для управления проектами, разработанную специально для команд, работающих в сфере разработки программного обеспечения, но успешно адаптир...